Split-half Method of Assessing Reliability
Using this method you take half the items, and correlate them with the other half and that correlation is the index of reliability. The assumption is that all the items are measuring a single variable. Because the items should be comparable they should be considered interchangeable. It should be noted, however, that is this interchanability that we are testing when we test reliability.
Only one subscales of the questionnaire is assessed in this problem (it takes up too much paper to do them all -- in the coefficient alpha below all subscales are assessed). The following "click" procedure with produce a syntax file that we will change slightly for our purposes. The "click" method will not give us exactly what we want.
Click Analyze.
Select Scale
Click Reliability Analysis.
Click the "Pull Down" box that has Alpha in it.
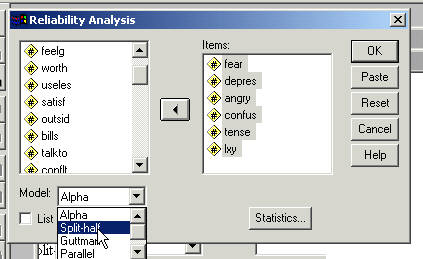
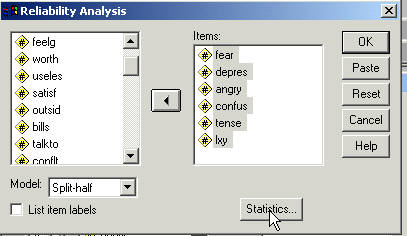
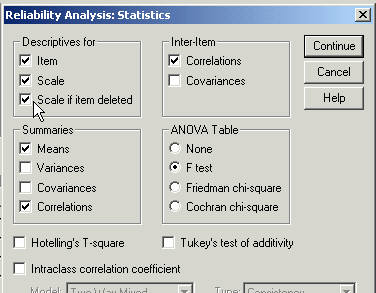
Click Statistics
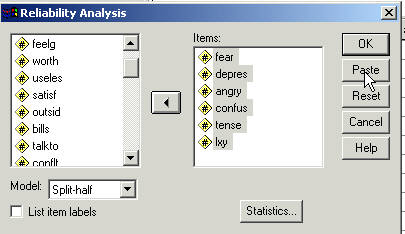
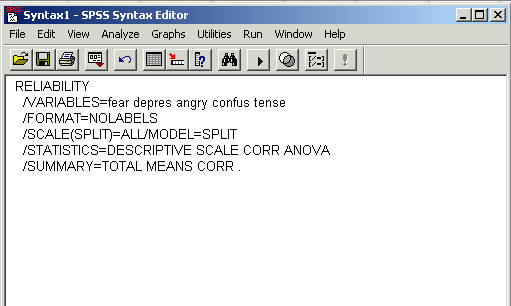
Where it says "/SCALE(SPLIT)=ALL/MODEL=SPLIT" you need to change it so it reads as follows:
"/SCALE(NegAffect)=ALL/MODEL=SPLIT".
Now in the printout the scale of fear, depres, angry, confuse, and tense will be lableled NegAffect.
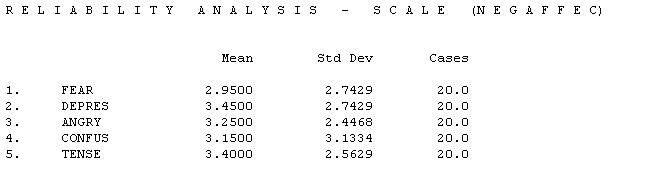
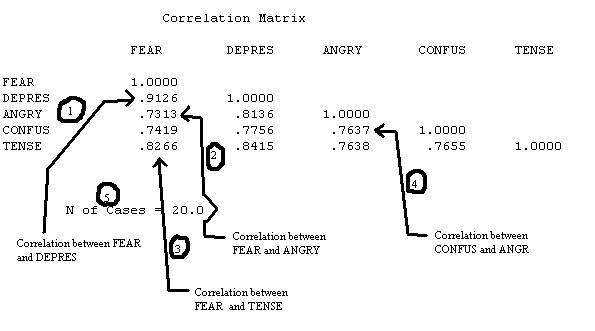
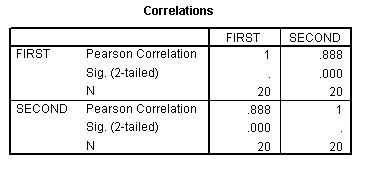
In the next section of the output there is the correlation matrix and the number of cases used in the computation. The number is the correlation between FEAR and DEPRES.
The number shows the number of cases.
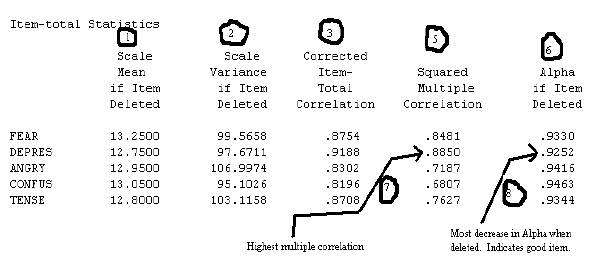

The Split-Half Reliability coefficient is the same as summing the items of the first half and summing the second half and then correlating the two results. This is demonstrated in the next example.